Podrška #17866
Zatvoren
harbour i vječna borba sa codepage-s
70%
Opis
kod ove funkcije postoji neki problem sa fontovima
Fajlovi
{kind=link}
{kind=link}
Povezani tiketi 2 (0 otvoreno — 2 zatvorenih)
 Izmjenjeno od Saša Vranić prije skoro 17 godina
Izmjenjeno od Saša Vranić prije skoro 17 godina
zadnje portiranje LD-a je dovelo do toga da uključimo gtqtc bibiloteku radi QT Console (qt konzole)
međutim ono što sam primjetio kod qt konzole je sljedeće
- ne radi resize - pa dobro i nije toliko bitno
- ne radi selektovanje copy - hajde i to može proći kao nebitno za početak
- box() funkcija ne ispisuje dobro karaktere popune forme, jednostavno puno je nekih plusića itd...
Izmjenjeno od Saša Vranić prije skoro 17 godina
gledao sam malo na net-u ima li šta vezano za ovaj problem, pa sam pronašao na nekim postovima kako se setuje jezik
pa sam to i testirao, pronašao sljedeće funkcije:
- REQUEST HB_CODEPAGE_
- hb_setcodepage("")
- hb_settermcp("")
pa sam pokušavao na razne načine ovo koristiti, međutim bez uspjeha
Izmjenjeno od Saša Vranić prije skoro 17 godina
još jedna bitna stvar je tastatura, ona nikako nije setovana kako treba, recimo tipke brojevi od 0 - 9 uopšte nerade !
Izmjenjeno od Saša Vranić prije skoro 17 godina
promjenom jezika nisam uspio ni ovaj problem rješiti
Izmjenjeno od Saša Vranić prije skoro 17 godina
pronašao sam ove info:
http://www.matrixlist.com/pipermail/harbour/2009-April/018710.html
hm, na tome se izgleda radi još !
Izmjenjeno od Saša Vranić prije skoro 17 godina
Izmjenjeno od Saša Vranić prije skoro 17 godina
- % završeno promijenjeno iz 0 u 10
Izmjenjeno od Saša Vranić prije skoro 17 godina
recimo u ld launcher.prg stavio da se prije svega setuje jezik
function Main(cKorisn,cSifra,p3,p4,p5,p6,p7)
// set language
REQUEST HB_CODEPAGE_HR1250
hb_setcodepage("HR1250")
hb_settermcp("HR1250",.t.)
MainLD(cKorisn,cSifra,p3,p4,p5,p6,p7)
return
a evo lista mogućih jezika, http://www.oohg.org/manual/htm/hb_setcodepage.htm
međutim kako rekoh, nisam uspio dobiti box() iscrtan kako treba
Izmjenjeno od Saša Vranić prije skoro 17 godina
probavao i sa ostalim jezicima, ista stvar, samo na box() dobijem neke drugačije znakove...
dakle, ima efekta ali ne mogu dobiti naš box() sa našim karakterima
 Izmjenjeno od Ernad Husremović prije više od 16 godina
Izmjenjeno od Ernad Husremović prije više od 16 godina
izgleda da se stvar out-of-box dobro ponaša na ubuntu-u ?
Izmjenjeno od Ernad Husremović prije više od 16 godina
bringout@nmraka-2:~/devel/work/fmk/harbour/harbour/doc/en-EN/lang.txt
* $SYNTAX$ * HB_TRANSLATE( <cSrcText>, [<cPageFrom>], [<cPageTo>] ) --> cDstText * $ARGUMENTS$ * <cSrcText> Is the source string to translate. * * <cPageFrom> Is the optional character code page ID of the source * string. If not specified, the default code page is used. * * <cPageTo> Is the optional character code page ID of the destination * string. If not specified, the default code page is used. * $RETURNS$ * HB_TRANSLATE() return destination string converted from the source * string. * $DESCRIPTION$ * HB_TRANSLATE() try to convert a source string from one code page * into the other. If a code page ID is not recognized, or not linked * in, the default code page is used. HB_TRANSLATE() is used usually * to convert between the Dos and the Windows code pages of the same * language. * * NOTE: If the source code page and target code page does not have * the same number of characters, a translation can not be done and * the destination string is a copy of the source string. * * NOTE: You must REQUEST every code page module you intend to use. * For example: to use the Russian RU866 code page you must add the * following to your program: REQUEST HB_CODEPAGE_RU866 * $EXAMPLES$ * REQUEST HB_CODEPAGE_DE * REQUEST HB_CODEPAGE_DEWIN * FUNCTION Main() * LOCAL cTxt := "A" + CHR( 142 ) + "BC" * ? "German 850 text:", cTxt * ? "German ANSI text:", HB_TRANSLATE( cTxt, "DE", "DEWIN" ) * RETURN NIL
Izmjenjeno od Ernad Husremović prije više od 16 godina
bringout@nmraka-2:~/devel/work/fmk/harbour/harbour/source/codepage$ ls *c
cpbg866.c cpdeiso.c cpeswinc.c cphu852s.c cpitwin.c cproiso.c cpskwin.c cpsvwin.c uc1006.c uc1256.c uc855.c uc866.c uc885916.c uc8859_8.c ucmacgrk.c cpbgiso.c cpdewin.c cpeswinm.c cphuiso.c cpltwin.c cprowin.c cpsl437.c cp_tpl.c uc1026.c uc1257.c uc856.c uc869.c uc88591b.c uc8859_9.c ucmacice.c cpbgmik.c cpel737.c cpfr850.c cphuisos.c cppl852.c cpru866.c cpsl852.c cptr857.c uc1125.c uc1258.c uc857.c uc874.c uc8859_1.c ucascii.c ucmacrom.c cpbgwin.c cpelwin.c cpfriso.c cphuwin.c cppliso.c cpruiso.c cpsliso.c cptrwin.c uc1250.c uc424.c uc860.c uc875.c uc8859_2.c ucatari.c ucmactrk.c cpcs852.c cpes850.c cpfrwin.c cphuwins.c cpplmaz.c cprukoi.c cpslwin.c cpua1125.c uc1251.c uc500.c uc861.c uc885910.c uc8859_3.c uckam.c ucmaz.c cpcsiso.c cpes850c.c cphr437.c cpit437.c cpplwin.c cpruwin.c cpsrwin.c cpua866.c uc1252.c uc737.c uc862.c uc885911.c uc8859_4.c uckoi8.c ucmik.c cpcskam.c cpesiso.c cphr852.c cpit850.c cppt850.c cpsk852.c cpsv850.c cpuakoi.c uc1253.c uc775.c uc863.c uc885913.c uc8859_5.c uckoi8u.c ucnext.c cpcswin.c cpesisoc.c cphrwin.c cpitisb.c cpptiso.c cpskiso.c cpsvclip.c cpuawin.c uc1254.c uc850.c uc864.c uc885914.c uc8859_6.c ucmacce.c cpde850.c cpeswin.c cphu852.c cpitiso.c cpro852.c cpskkam.c cpsviso.c uc037.c uc1255.c uc852.c uc865.c uc885915.c uc8859_7.c ucmaccyr.c
Izmjenjeno od Ernad Husremović prije više od 16 godina
tako za hrvatski imamo 852 i windows 1250 code page
cphr852.c cphrwin.c
dok za slovence
bringout@nmraka-2:~/devel/work/fmk/harbour/harbour/source/codepage$ ls sl
cpsl437.c cpsl852.c cpsliso.c cpslwin.c
Izmjenjeno od Ernad Husremović prije više od 16 godina
i tu imamo ovo recimo
cpsliso.c
...
/* Language name: Slovenian */
/* ISO language code (2 chars): SL */
/* Codepage: ISO-8859-2 */
#include "hbapi.h"
#include "hbapicdp.h"
#define NUMBER_OF_CHARACTERS 31 /* The number of single characters in the
alphabet, two-as-one aren't considered
here, accented - are considered. */
#define IS_LATIN 1 /* Should be 1, if the national alphabet
is based on Latin */
#define ACCENTED_EQUAL 0 /* Should be 1, if accented character
has the same weight as appropriate
unaccented. */
#define ACCENTED_INTERLEAVED 0 /* Should be 1, if accented characters
sort after their unaccented counterparts
only if the unaccented versions of all
characters being compared are the same
( interleaving ) */
...
/* If ACCENTED_EQUAL or ACCENTED_INTERLEAVED is 1, you need to mark the
accented characters with the symbol '~' before each of them, for example:
a~<80>
If there is two-character sequence, which is considered as one, it should
be marked with '.' before and after it, for example:
... h.ch.i ...
The Upper case string and the Lower case string should be absolutely the
same excepting the characters case, of course.
*/
static HB_CODEPAGE s_codepage = { "SLISO",
HB_CPID_8859_2, HB_UNITB_8859_2, NUMBER_OF_CHARACTERS,
"ABCÈÆDÐEFGHIJKLMNOPQRS©TUVWZ®XY",
"abcèædðefghijklmnopqrs¹tuvwz¾xy",
IS_LATIN, ACCENTED_EQUAL, ACCENTED_INTERLEAVED, 0, 0, NULL, NULL, NULL, NULL, 0, NULL };
HB_CODEPAGE_INIT( SLISO )
...
Izmjenjeno od Ernad Husremović prije više od 16 godina
fajlovi koji počinju sa uc su unicode konverzija
uc852.c sadrži konverziju između cp 852 i unicode znakoav
* Harbour Project source code: * IBM852 <-> Unicode conversion table * * Copyright 2003 Przemyslaw Czerpak <druzus@acn.waw.pl> * www - http://www.xharbour.org
Izmjenjeno od Ernad Husremović prije više od 16 godina
koristan email od Victor-a jednog od glavnih glava harbour projekta.
> the named code page ESMWIN is the correct to use at ansi spanish
> applications. all other are invalids to work or only to read old buggy
> indexes incorrect ordered.
"ANSI" means Windows in this context.
> ESMWIN is based on:
>
> Windows locale: Spanish (Modern Sort)
> Locale ID: 0xC0A
> Location designator: Modern_Spanish
> Code page: 1252
> Code page name: windows-1252
>
> you can read the next tables and see how incorrect is to use ISO-????.
> CERTANLLY ESMWIN needs to change its code page name to windows-1252
I'll correct the CP in those files then, thank you.
I still fail to see however, how cpesisom is any
worse than cpeswinm (or mwin), if their content is
exactly the same, just linked to the ISO CP (which is again the same as Windows-1252 CP, except the name).
Please explain.
[ Update: I became clear later. ]
> ESWIN is a ansi copy of its oem version es850 compatible with old
> collation used in CL53
> but incorrectly ordered an unusable in Spain for this reason.
Okay, so they probably need to be called ESWINC, ES850C and
ESISOC to say, these are indeed Clipper compatibility codepages,
and at the same time rename to rename 'Modern' ES*M to ESWIN,
ESISO, because these seem to be the correct Spanish collations,
which everyone like to use. Thanks for the clarification.
If that's the case, I'd opt to clear this up in the repo.
It may also be useful to add an ES850 according to the 'Modern' collation, so that Spanish users can still use
HB_TRANSLATE() to convert strings between "OEM" and "ANSI"
codepages.
> I don't know enough Linux, but the next is the windows information:
>
> 1) first of all this files are not code page, are collations.
Yes, I know, but they are using some sort of codepage anyway.
This codepage is indicated in various places in the files, plus the collation strings are expected to be encoded in this CP.
> 2) theorically DBF are created to contain oem code page. But
> actually the great part of windows applications save ansi code page at this files
> without problem or conflict.
I think the CP used in a given app is completely up to the <<<<<<<<<<<<<<<<<<<<<< bitno
actual app / user. DBF itself can store any binary data, <<<<<<<<<<<<<<<<<<<<<<
even UTF16 or UTF8. The developers' job is to choose one
and use it consistently and sync the app settings to match
the used .dbfs.
> 3) there are different code page OEM, ANSI, UTF8( UNICODE ), ... all
> of them has its different collate.
Actually the collation (= ordering of national alphabet)
is one and only for a given language (at least theoretically).
Their internal representation (actual bytes used to represent national chars) depends on the CP used.
Notice that multiple collations _may_ still exist for various reasons, the major
one being Clipper compatibility, or compatibility with other
products which weren't closely following the national standard.
(as discussed above). Another reason can be different "official"
and "unofficial" standards (and who knows what else).
It's important to keep the collation the exact same across
different CPs, otherwise HB_TRANSLATE() won't be able to
convert between them.
All in all, the above is the reason why we have multiple
cpes*.c files: same collation, different CP. Or, in case of
HU, there are two sets of collations (one Clipper compatible,
one Successware Six compatible), both with multiple CPs.
And this seems to be the case for Spanish, too.
Also, instead of "OEM" and "ANSI", - which are pretty vague,
Windows specific and non-standard terms - I'd suggest to use
'IBM/MS-DOS codepage' (~ "OEM") and 'Windows codepage' (~ "ANSI") <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<,,
terms.
> Code page Description
> 1258 Vietnamese
> 1257 Baltic
> 1256 Arabic
> 1255 Hebrew
> 1254 Turkish
> 1253 Greek
> 1252 Latin1 (ANSI)
> 1251 Cyrillic
> 1250 Central European
> 950 Chinese (Traditional)
> 949 Korean
> 936 Chinese (Simplified)
> 932 Japanese
> 874 Thai
> 850 Multilingual (MS-DOS Latin1)
> 437 MS-DOS U.S. English
See these in uc*.c files. I've added support for
all of them except the 900 range (which doesn't
seem to fit in current Harbour).
> 'CodePage identifier and name BrDisp BrSave MNDisp
> MNSave 1-Byte ReadOnly
> '65006 utf-32BE False False False
> False False True '
We should use the 'identifier and name', I'm not sure
though if they are all the correct ones in this list.
There is a 'main' name most of the time and lots of
aliases for the same CP, we should try to use the main
one.
> Windows locale LCID (locale ID) Collation designator Code page
This falls outside of Harbour scope, as it's Windows-only.
But the list is good to get an idea on which Language uses
what CP.
Thanks for clarifying the ES issues.
To me it looks like we'd need to do three things:
1) Fix the internal CP in current ESWIN and ESWINM files.
(I'll do this ASAP)
2) Rename Clipper compatibility ESWIN, ESISO, ES850 files
to ESWINC, ESISOC, ES850C and add comment that these
are 'legacy' or Clipper compatibility ones (someone
should test which is true). Rename ESWINM and ESISOM
to ESWIN, ESISO.
3) Add ES850 according to the 'modern' collation.
Izmjenjeno od Ernad Husremović prije više od 16 godina
napisao ovaj program:
bringout@nmraka-2:~/fin$ cat test_write.prg
procedure Main() REQUEST DBFCDX use konto append blank replace id with "10", naz with "šŠ ćĆ đĐ čČ žŽ" go top do while !eof() ? id, naz skip end inkey(0)
Sa vi otvorio konto.dbf, sve mi ukazuje da se radi o utf-8 zapisu.
interesantno ...
bringout@nmraka-2:~/fin$ hbmk2 -gttrm test_write.prg <<<<<<<<<<<<<<<<<<<<<<<<< GTTRM hbmk: Processing configuration: /usr/bin/hbmk.cfg Harbour 2.0.0beta2 (Rev. -1) Copyright (c) 1999-2009, http://www.harbour-project.org/ Compiling 'test_write.prg'... Lines 18, Functions/Procedures 1 Generating C source output to 'test_write.c'... Done. bringout@nmraka-2:~/fin$ ./test_write 2120 KUPCI U ZEMLJI º-z ª-Z 5410 99999 TEST 10 ernad husremovi─ç 10 ┼í┼á ─ç─å ─æ─É ─ì─î ┼╛┼╜ <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<< vidimo da je svako slovo kao dva znaka, definitivno utf-8 10 ┼í┼á ─ç─å ─æ─É ─ì─î ┼╛┼╜ 10 ┼í┼á ─ç─å ─æ─É ─ì─î ┼╛┼╜ 10 ┼í┼á ─ç─å ─æ─É ─ì─î ┼╛┼╜ 10 ┼í┼á ─ç─å ─æ─É ─ì─î ┼╛┼╜ bringout@nmraka-2:~/fin$ hbmk2 -gtstd test_write.prg <<<<<<<<<<<<<<<<<<<<<<<<<< GTSTD hbmk: Processing configuration: /usr/bin/hbmk.cfg Harbour 2.0.0beta2 (Rev. -1) Copyright (c) 1999-2009, http://www.harbour-project.org/ Compiling 'test_write.prg'... Lines 18, Functions/Procedures 1 Generating C source output to 'test_write.c'... Done. bringout@nmraka-2:~/fin$ ./test_write 2120 KUPCI U ZEMLJI �-z �-Z <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<< ovo je upisano sa gtqtc sa fin harbour-om 5410 99999 TEST 10 ernad husremović 10 šŠ ćĆ đĐ čČ žŽ <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<< naša slova dobra, utf-8 10 šŠ ćĆ đĐ čČ žŽ 10 šŠ ćĆ đĐ čČ žŽ 10 šŠ ćĆ đĐ čČ žŽ 10 šŠ ćĆ đĐ čČ žŽ 10 šŠ ćĆ đĐ čČ žŽZaključci:
- fmk/fin gtqtc harbour kod zapisivanja vrši nekakvu konverziju i ne upisuje utf-8
- međutim kada naredimo zapis utf-8 stringa, dbf ga bez problema "proguta"
Izmjenjeno od Ernad Husremović prije više od 16 godina
pokušao sistemom nabadanja, ali ne znam kako se navodi UTF-8 u ovoj konverziji. Izgleda nikako
bringout@nmraka-2:~/fin$ cat test_write.prg
procedure Main() REQUEST DBFCDX //REQUEST HB_CODEPAGE_SL REQUEST HB_CODEPAGE_SLWIN REQUEST HB_CODEPAGE_SLISO REQUEST HB_CODEPAGE_SL852 use konto append blank replace id with "10", naz with "šŠ ćĆ đĐ čČ žŽ" go top do while !eof() ? id, "0: " + naz ? "1: " + HB_TRANSLATE( naz, "SLISO", "SLWIN"), "2: " + HB_TRANSLATE( naz, "SL852", "SLISO") ? "3: " + HB_TRANSLATE( naz, "SLISO", "UTF-8"), "4: " + HB_TRANSLATE( naz, "SLWIN", "UTF-8"), "5: " + HB_TRANSLATE( naz, "SL852", "UTF-8") ? "-------------------------------------------------------------------------------------------" skip end inkey(0)
Izmjenjeno od Ernad Husremović prije više od 16 godina
- Naslov promijenjeno iz Harbour gtqtc i box() funkcija u vječna borba sa codepage-s
Izmjenjeno od Ernad Husremović prije više od 16 godina
http://muzso.hu/2009/02/17/how-to-use-hungarian-locale-and-keyboard-layout-in-wine-with-ubuntu
bringout@nmraka-2:~/fin$ vi /usr/share/i18n/SUPPORTED
bringout@nmraka-2:~/fin$ sudo vi /var/lib/locales/supported.d/local
bringout@nmraka-2:~/fin$ cat /var/lib/locales/supported.d/local
bs_BA.UTF-8 UTF-8 bs_BA ISO-8859-2
bringout@nmraka-2:~/fin$ sudo dpkg-reconfigure locales
perl: warning: Setting locale failed.
perl: warning: Please check that your locale settings:
LANGUAGE = (unset),
LC_ALL = (unset),
LANG = "bs_BA.ISO-8859-2"
are supported and installed on your system.
perl: warning: Falling back to the standard locale ("C").
locale: Cannot set LC_CTYPE to default locale: No such file or directory
locale: Cannot set LC_MESSAGES to default locale: No such file or directory
locale: Cannot set LC_ALL to default locale: No such file or directory
Generating locales...
aa_DJ.UTF-8... done
aa_ER.UTF-8... done
aa_ER.UTF-8@saaho... done
aa_ET.UTF-8... done
bs_BA.ISO-8859-2... done
bs_BA.UTF-8... up-to-date
Generation complete.
Izmjenjeno od Ernad Husremović prije više od 16 godina
kada sam stavio
bringout@nmraka-2:~/fin$ export LANG=bs_BA.ISO-8859-2
i otvorio u vi-u gornji fajl: dobio sam ovo
append blank replace id with "10", naz with "�� �� �� �� ��" <<<<<<<<<<<<<<<<<<<<<< jer je izvorno pisano sa UTF-8 endcodings go top do while !eof() ? id, "0: " + naz ? "1: " + HB_TRANSLATE( naz, "SLISO", "SLWIN"), "2: " + HB_TRANSLATE( naz, "SL852", "SLISO") ? "3: " + HB_TRANSLATE( naz, "SLISO", "UTF8"), "4: " + HB_TRANSLATE( naz, "SLWIN", "UTF8"), "5: " + HB_TRANSLATE( naz, "SL852", "UTF8") ? "-------------------------------------------------------------------------------------------" skip end inkey(0)
Izmjenjeno od Ernad Husremović prije više od 16 godina
kada sam napravio reindex u fin, šifrarnik koonta mi se osvježio sa ovim stavkama što sam sa test_write zapisivao i u prikazu sam dobio (umjesto šŠ itd ...):
šŠ ćĆ đĐ čČ žŽ
Izmjenjeno od Ernad Husremović prije više od 16 godina
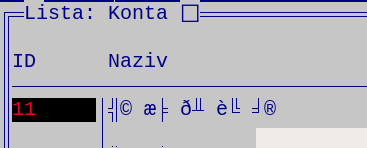
- Fajl iso-8859-2_tekst_u_fin.png iso-8859-2_tekst_u_fin.png dodano
kada sam napravio test_write_iso.prg
i u njemu stavio replace id with "11", naz with "šŠ ćĆ đĐ čČ žŽ"
ali fajl snimoio u gedit-u kao iso-8859-2.fajl
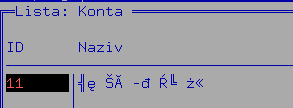
Kada sam ovaj šifrarnik odštampao i otvorio u gedit-u dobio sam naša slova.
Izmjenjeno od Ernad Husremović prije više od 16 godina
idem sada vidjeti što sa vi-om ne mogu raditi edit ovog iso-8859-2 fajla http://automatthias.wordpress.com/2006/07/18/vim-utf-8-and-iso-8859-2/
Izmjenjeno od Ernad Husremović prije više od 16 godina
podesio prema uputama na blog-u, dodao latin-2 i radi ko melčin horoz
bringout@nmraka-2:~/fin$ cat /home/bringout/.vimrc
set fileencodings=utf-8,latin2
Izmjenjeno od Ernad Husremović prije više od 16 godina
- Fajl harbour_termcp_sl_iso.png harbour_termcp_sl_iso.png dodano
- Fajl harbour_termcp_sl_iso_2.png harbour_termcp_sl_iso_2.png dodano
kako je to u fmk_lib
fmk_skeleton/skeleton.prg
#ifdef __PLATFORM__LINUX
REQUEST HB_CODEPAGE_SL852
REQUEST HB_CODEPAGE_SLISO
hb_setCodePage( "SL852" )
hb_setTermCP("SLISO")
#else
ovdje je sve komentirano
#endif
promjenio sam i stavio hb_setCodePage("SLISO") pa buildao
i dobio sam rezultate slične windows-ima:- grafički znakovi nisu dobro prikazani
- tastatura je praktično van funkcije (naša slova, broj jedan ...)
To je to ...
Izmjenjeno od Ernad Husremović prije više od 16 godina
istu stvar sam dobio kada sam setovao
bringout@nmraka-2:~/devel/work/fmk/fin$ export LANG=bs_BA.ISO-8859-2
Izmjenjeno od Ernad Husremović prije više od 16 godina
jao tek kasnije sam uočio (usporedbom slika) da sam ja ovo ranije radio sa
skeleton.prg
#ifdef __PLATFORM__WINDOWS //REQUEST HB_GT_WIN //REQUEST HB_GT_GTQTC_DEFAULT #else //REQUEST HB_GT_CRS REQUEST HB_GT_XWC_DEFAULT <<<<<<<<<<< GTXWC #endif
gtxwc konzolom, a ne sa gqtc konzolom :(
gtxwc konzola zna handilrati sa našim slovama i uvažava postavke setovane sa hb_setTerminalCp, hb_setCodePage, dok gtqtc konzola to ignoriše.
zapažanje: GTXWC konzola je znatno brža što se tiče refresh-a ekrana od gtqtc konzole
Izmjenjeno od Ernad Husremović prije više od 16 godina
bringout@nmraka-2:~/devel/work/fmk/harbour/harbour/include$ vi hbapicdp.h
typedef struct _HB_CODEPAGE
{
const char * id;
const char * uniID;
PHB_UNITABLE uniTable;
int nChars;
const char * CharsUpper;
const char * CharsLower;
BOOL lLatin;
BOOL lAccEqual;
BOOL lAccInterleave;
BOOL lSort;
BOOL lChClone;
BYTE * s_chars;
BYTE * s_upper;
BYTE * s_lower;
BYTE * s_accent;
int nMulti;
PHB_MULTICHAR multi;
} HB_CODEPAGE, * PHB_CODEPAGE;
#define HB_CPID_437 "cp437"
#define HB_CPID_737 "cp737"
#define HB_CPID_775 "cp775"
#define HB_CPID_850 "cp850"
#define HB_CPID_852 "cp852"
...
#define HB_CPID_861 "cp861"
#define HB_CPID_862 "cp862"
#define HB_CPID_863 "cp863"
#define HB_CPID_864 "cp864"
#define HB_CPID_1250 "cp1250"
#define HB_CPID_1251 "cp1251"
#define HB_CPID_1252 "cp1252"
#define HB_CPID_1253 "cp1253"
....
#define HB_CPID_1257 "cp1257"
#define HB_CPID_1258 "cp1258"
#define HB_CPID_8859_1 "iso8859-1"
#define HB_CPID_8859_1B "iso8859-1b"
...
#define HB_CPID_8859_15 "iso8859-15"
extern HB_EXPORT PHB_CODEPAGE hb_vmCDP( void );
extern HB_EXPORT void hb_vmSetCDP( PHB_CODEPAGE pCDP );
extern HB_EXPORT BOOL hb_cdpRegister( PHB_CODEPAGE );
extern HB_EXPORT const char * hb_cdpSelectID( const char * );
extern HB_EXPORT const char * hb_cdpID( void );
extern HB_EXPORT PHB_CODEPAGE hb_cdpSelect( PHB_CODEPAGE );
extern HB_EXPORT PHB_CODEPAGE hb_cdpFind( const char * );
extern HB_EXPORT void hb_cdpTranslate( char *, PHB_CODEPAGE, PHB_CODEPAGE );
extern HB_EXPORT void hb_cdpnTranslate( char *, PHB_CODEPAGE, PHB_CODEPAGE, ULONG );
extern HB_EXPORT int hb_cdpcmp( const char *, ULONG, const char *, ULONG, PHB_CODEPAGE, BOOL );
extern HB_EXPORT int hb_cdpicmp( const char *, ULONG, const char *, ULONG, PHB_CODEPAGE, BOOL );
extern HB_EXPORT int hb_cdpchrcmp( char, char, PHB_CODEPAGE );
extern HB_EXPORT void hb_cdpReleaseAll( void );
extern HB_EXPORT USHORT hb_cdpGetU16( PHB_CODEPAGE, BOOL, UCHAR );
extern HB_EXPORT UCHAR hb_cdpGetChar( PHB_CODEPAGE, BOOL, USHORT );
extern HB_EXPORT BOOL hb_cdpGetFromUTF8( PHB_CODEPAGE, BOOL, UCHAR, int *, USHORT * );
extern HB_EXPORT ULONG hb_cdpStrnToUTF8( PHB_CODEPAGE, BOOL, const char *, ULONG, char * );
extern HB_EXPORT ULONG hb_cdpStrnToU16( PHB_CODEPAGE, BOOL, const char *, ULONG, char * );
extern HB_EXPORT ULONG hb_cdpStringInUTF8Length( PHB_CODEPAGE, BOOL, const char *, ULONG );
extern HB_EXPORT ULONG hb_cdpUTF8ToStrn( PHB_CODEPAGE, BOOL, const char *, ULONG, char *, ULONG );
extern HB_EXPORT ULONG hb_cdpUTF8StringLength( const char *, ULONG );
extern HB_EXPORT char * hb_cdpUTF8StringSubstr( const char *, ULONG, ULONG, ULONG, ULONG * );
extern HB_EXPORT ULONG hb_cdpUTF8StringPeek( const char *, ULONG, ULONG );
Izmjenjeno od Ernad Husremović prije više od 16 godina
- Naslov promijenjeno iz vječna borba sa codepage-s u harbour i vječna borba sa codepage-s
očigledno da se mora pogledati u ~/devel/work/fmk/harbour/harbour/source/rtl/gtxwc/gtxwc.c koji je bolje rješen
#ifndef HB_CDP_SUPPORT_OFF
if( wnd->inCDP && wnd->hostCDP && wnd->inCDP != wnd->hostCDP )
{
hb_cdpnTranslate( (char *) buf, wnd->inCDP, wnd->hostCDP, n );
}
#endif
Izmjenjeno od Ernad Husremović prije više od 16 godina
gtqtcc bilješke¶
hb_gt_wvt_QTranslateKeyAlpha - alphanumeric
hb_gt_wvt_QTranslateKeyKP - key keypad
hb_gt_wvt_QTranslateDigit
hb_gt_wvt_QTranslateKey
cdpTerm - codepage terminal, cdpHost - host codepage
Izmjenjeno od Ernad Husremović prije više od 16 godina
static void hb_gt_wvt_QTranslateKeyAlpha( PHB_GTWVT pWVT, Qt::KeyboardModifiers kbm, int key, int shiftkey, int altkey, int controlkey, QString text )
{
HB_SYMBOL_UNUSED( key );
HB_SYMBOL_UNUSED( shiftkey );
HB_SYMBOL_UNUSED( controlkey );
if( kbm & Qt::AltModifier )
hb_gt_wvt_AddCharToInputQueue( pWVT, altkey );
else
{
if( kbm & Qt::ControlModifier )
hb_gt_wvt_AddCharToInputQueue( pWVT, controlkey );
else
hb_gt_wvt_AddCharToInputQueue( pWVT, ( int ) *text.toLatin1().data() ); <<<<<<<<<<<<<<<<<<<<<<<<< toLatin1
}
}
Izmjenjeno od Ernad Husremović prije više od 16 godina
sa ovim test.prg sam eksperimentisao i gledao kako gtqtc radi
bringout@nmraka-2:~/devel/work/fmk$ cat test.prg
procedure main() cTest := SPACE(50) @ 10, 10 SAY "HELLO from Ernad Husremović" GET cTest READ
u samom cpp sam stavio unutar static void hb_gt_wvt_QTranslateKey( PHB_GTWVT pWVT, Qt::KeyboardModifiers kbm, int key, int shiftkey, int altkey, int controlkey )
printf:
...
default :
{
printf("key %d", event->key()); <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
hb_gt_wvt_AddCharToInputQueue( pWVT, c );
return;
//if( ( event->key() >= 0 ) && ( event->key() <= 255 ) )
if ( event->key() >= 0 )
//hb_gt_wvt_QTranslateKeyAlpha( pWVT, kbm, 'Z', 'z', K_ALT_Z, K_CTRL_Z, event->text() );
//return;
c = event->key();
else
{
QWidget::keyPressEvent( event );
return ;
}
}
}
hb_gt_wvt_AddCharToInputQueue( pWVT, c );
pa sam za "ž" npr dobio "key 381"
Izmjenjeno od Ernad Husremović prije više od 16 godina
ukratko ovaj gtqtc handlira samo latin1 karaktere a ovo ostalo ignoriše. Kada je tastatura nestandardna dodatno pravi zbrku i na normalnim znakovima npr "1"
Izmjenjeno od Ernad Husremović prije više od 16 godina
GTTRM¶
Iz harbour ChangeLog-a
added new GT driver - it's terminal driver like GTCRS and GTSLN but it does not use any external library like [N]CURSES or SLANG so it can be compiled in nearly all POSIX systems. It's not such flexible like curses or slang base drivers because instead of using termcap/terminfo databases to extract terminal capabilities it uses some hard coded sequences for few terminals (now Linux, ANSI, XTERM) but it should cover users requests in 95% of cases. Terminals I tested are quite well supported (GTTRM works even better then GTCRS or GTSLN and is much faster in full screen mode - 2-4 times).
I noticed that most terminal emulators works much better with GTTRM then with GTCRS or GTSLN due to limited list of used escape sequences so some minor differences in each terminal implementation are not noticeable. GTTRM automatically detects ISO/UTF8 terminal mode and chose valid output what should also help *nix users. Now I would like to ask BSD and MacOSX users to test GTTRM in these systems with pure text console and XWindow terminal emulators. I'm interesting in any problems you may found.
Izmjenjeno od Ernad Husremović prije više od 16 godina
- Status promijenjeno iz Novo u Dodijeljeno
- Odgovorna osoba promijenjeno iz Saša Vranić u Ernad Husremović
On Fri, 24 Apr 2009, Alexander S.Kresin wrote:
Hi,
> for a few years I use for Harbour Linux console applications the gtcrs,
> but last time more and more new distributions goes with UTF8 coding and
> gtcrs doesn't show national characters ( possibly, ncursesw should be used
> instead of ncurses, but this is other issue ).
In the past I created GTCRW but I haven't committed it due to ncursesw
limitations for which I have to create a lot of workarounds. With current
GT model it can be implemented much easier but I do not know if it's worth
to invest time for it. See below.
> Which gt can I use now with distributions, based on UTF8, to see national
> characters properly ?
1. GTTRM it's terminal GT which does not use curses or slang and does not
use termcap/terminfo database. It supports only few most popular terminals
XTERM/LINUX/ANSI.
It automatically detects UTF8/ISO terminal mode and works well with both.
It also should work well as simple GTSTD as long as you do not use some
full screen command but will operate only on console output.
Probably GTTRM is the best as default choice until you do not have to
use some exotic terminals or some seldom used *nix ports.
2. GTSLN with slang 1.4.x + Unicode patches or with slang2 which has native
support for UTF8. GTSLN supports both slang versions.
> I've tried gtxwc, but, most likely, I've missed something, and cyrillic
> characters was showed incorrectly, too. SO the second question is - what I
> need to set ( codepage, font, something other ... ) to see cyrillic letters
> properly with gtxwc ?
You have to inform GT driver about codepage you are using in your source
GT output so it can make conversion to unicode values. See HB_SETTERMCP()
2006-02-04 17:05 UTC+0100 Przemyslaw Czerpak (druzus/at/priv.onet.pl)
[...]
The new three .prg functions:
HB_SETKEYCP( <cTermCP> [,<cHostCP>] )
HB_SETDISPCP( <cTermCP> [,<cHostCP>] [,<lBoxChar>] )
HB_SETTERMCP( <cTermCP> [,<cHostCP>] [,<lBoxChar>] )
have been added. They set automatic input (HB_SETKEYCP)
and output (HB_SETDISPCP) (or both: HB_SETTERMCP) character
translation. They are also important for some GTs which
informing them about used internal code page for unicode
translation (GTXWC, GTSLN) and/or chosing proper character
set (standard/alternate) for letters and other (f.e. box
drawing characters) (GTCRS, GTSLN),
<cTermCP> is encoding used on external (terminal) side
<cHostCP> is encoding used internally, if not given then
current code page set HB_SETCODEPAGE() is used.
some of GTs which uses unicode output may
ignore <cTermCP>
<lBoxChar> is optional parameter which interacts with dispbox()
output disabling switching to alternate character
set in some GTs. It effectively causes that if internal
(host) code page contains some letters on the box char
positions then they will be shown also by box drawing
functions like dispbox() instead of CP437 characters.
In some cases it could be useful. By default lBoxChar
is not set and GTs which can switch between standard
and alternate character set (GTCRS, GTSLN) will try to
use alternate character set for box drawing functions.
To the above list of GTs you should add GTTRM (added later) and Unicde builds
of some windows only GTs like GTWVT.
Probably in your case it will be enough to make sth like:
HB_SETTERMCP( "RUISO", "RUISO" )
best regards,
Przemek
Izmjenjeno od Ernad Husremović prije više od 16 godina
bringout@nmraka-2:~/devel/work/fmk/harbour/harbour/source/rtl$ grep HB_FUNC cdpapi.c
HB_FUNC( HB_CDPSELECT ) HB_FUNC( HB_CDPUNIID ) HB_FUNC( HB_SETCODEPAGE ) HB_FUNC( HB_TRANSLATE ) HB_FUNC( HB_CDPLIST ) HB_FUNC( HB_STRTOUTF8 ) HB_FUNC( HB_UTF8CHR ) HB_FUNC( HB_UTF8TOSTR ) HB_FUNC( HB_UTF8SUBSTR ) HB_FUNC( HB_UTF8LEFT ) HB_FUNC( HB_UTF8RIGHT ) HB_FUNC( HB_UTF8PEEK ) HB_FUNC( HB_UTF8POKE ) HB_FUNC( HB_UTF8STUFF ) HB_FUNC( HB_UTF8LEN ) HB_FUNC( HB_UTF8STRTRAN )
Izmjenjeno od Ernad Husremović prije više od 16 godina
gttrm¶
najviše mi je gttrm i ovaj source pomogao da skontam gdje šta hoda što se tiče kodnih stranica i UTF8
bringout@nmraka-2:~/devel/work/hernads-labs/qt-labs/hb$ vi test_3.prg
#include "hbgtinfo.ch"
#include "inkey.ch"
#include "box.ch"
REQUEST HB_CODEPAGE_SLISO
REQUEST HB_CODEPAGE_SL852
REQUEST HB_CODEPAGE_SLWIN
Hb_GtInfo( HB_GTI_WINTITLE, "hello world" )
//? Hb_GtInfo( HB_GTI_ISUNICODE, .t. )
? "isunicode =", Hb_GtInfo( HB_GTI_ISUNICODE )
// used internaly
cHostCP := "SL852"
//hb_settermcp("SL852")
cTermCP := "SLISO"
hb_setcodepage(cHostCp)
HB_SETTERMCP(cTermCp, cHostCP)
cStr1 := hb_UTF8ToSTR("Ernad Husremović")
cGet = PADR(" ", 50)
// 0x86 - cacute
cStr2 = "Ernad Husremovi" + CHR(134)
? cStr2, LEN(cStr2), hb_STRToUTF8(cStr2), LEN(hb_StrToUTF8(cStr2)), hb_UTF8LEN(hb_StrToUTF8(cStr2))
inkey(0)
? cStr1, cStr2, cStr1 == cStr2
inkey(0)
evo šta sam dobio:
isunicode = .T. Ernad Husremović 16 Ernad Husremovi─ç 17 16
Izmjenjeno od Ernad Husremović prije više od 16 godina
- % završeno promijenjeno iz 10 u 70
da bih uradio #18111 sa gttrm na ovo neću do daljnjeg trošiti vrijeme.
Izmjenjeno od Ernad Husremović prije više od 16 godina
skontao sam glavne stvar sa kodnim stranicama problem je što gtqtc jednostavno to nema razrađeno, ali na to sada ne vrijedi trošiti vrijeme.
Izmjenjeno od Ernad Husremović prije skoro 16 godina
- Status promijenjeno iz Dodijeljeno u Zatvoreno